The Importance of Real-time Observability in Notification Systems
Notifications fail silently, leaving you in the dark even when your system says 'sent.' Real-time observability transforms this black box, letting you trace every message and instantly find the root cause of delivery failures, from provider errors to device-side issues.

Push notifications are among the core features in almost every app nowadays, but troubleshooting them can be a nightmare. Imagine this scenario: the users are reporting that they aren’t receiving anything, but nothing seems to be an issue on your end. The truth is, though, there are dozens of potential failure points between sending a request and the user seeing a notification. Without real-time observability into the entire system, pinpointing where things break down is almost impossible.
What Does Observability Bring to Developers?
Observability is all about answering questions you didn't even know you'd need to ask. Unlike monitoring, which is limited to tracking known issues, observability provides you with multiple ways to understand complex (and often unexpected) behaviors of systems in production.
Real-time observability is capable of transforming notification systems from black-box pipelines into debuggable and analyzable components of your infrastructure. For instance, when a user reports "I haven’t received a notification," observability enables precise debugging by letting you trace that specific notification. You can then identify whether it failed at the API layer, was rejected by the push provider, or was delivered but not displayed due to device settings.
Observability also reveals patterns beyond individual issues thanks to analytics intelligence. Are iOS users experiencing higher failure rates? Do notifications sent at 3 p.m. have better delivery rates? Which notification types drive the most user engagement? By finding out the answers to these questions, you will learn what is working and what isn’t.
Why Is Observability Important for Notification Systems?
Without observability, notification delivery is a black box. You just send a request to a push service and hope for the best. When users report missing notifications, you’re left with no data to investigate what went wrong.
Even though failures are inevitable, observability gives you tools to detect them and respond to them effectively. Usually, it is implemented through platforms like Datadog or AWS CloudWatch, which collect metrics, logs, and traces from your applications. Open-source alternatives like Prometheus and Grafana are also widely used. These tools help you understand what's happening inside your systems by tracking performance metrics, error rates, latency distributions, and system behavior patterns.
The main page of all the observability solutions is a dashboard that allows you to overview the state of the whole system:
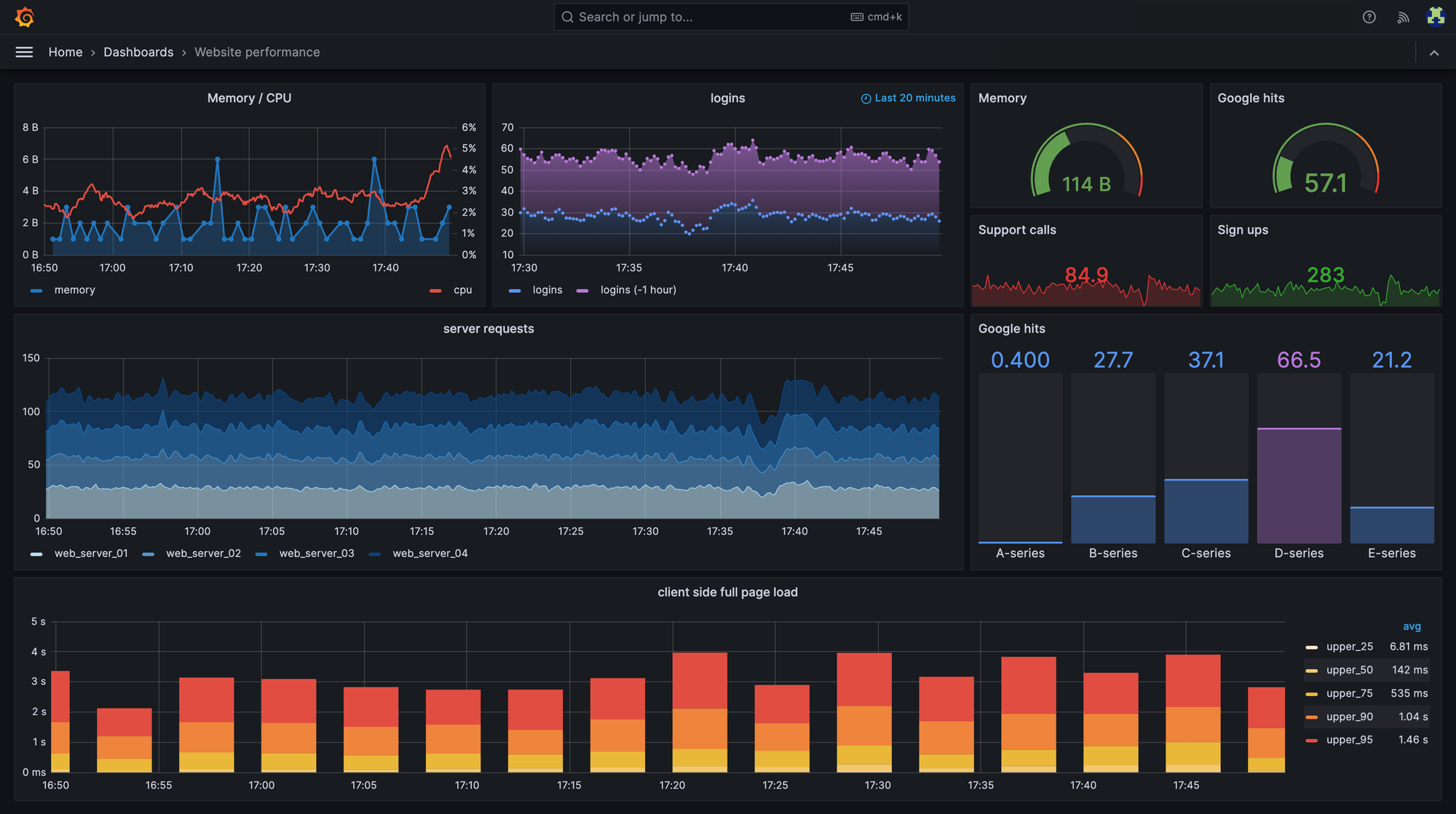
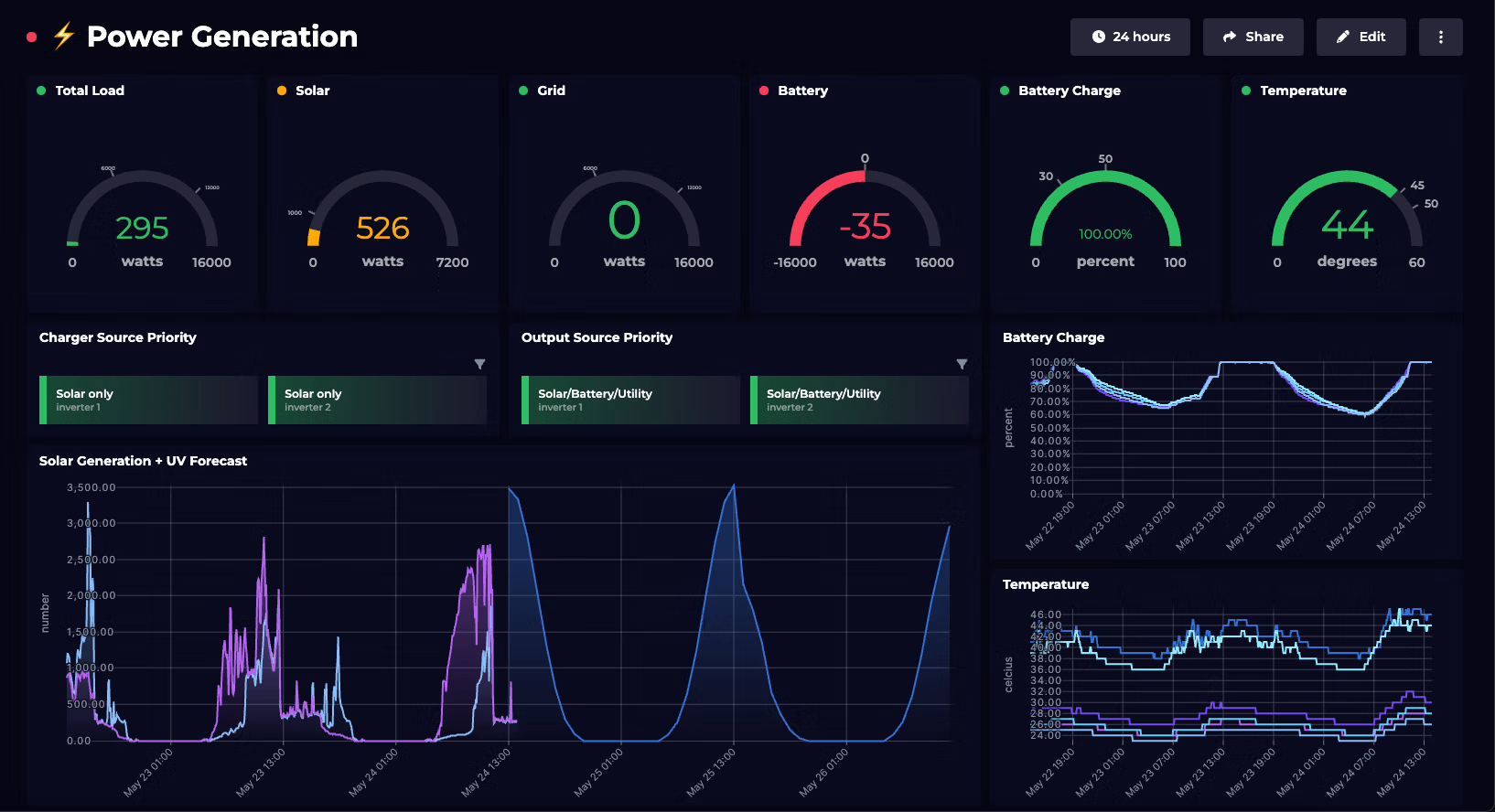
In the context of notifications, observability tools reveal specific failure patterns that would otherwise remain hidden. When notification pipelines track metrics like delivery rates, retry attempts, and error codes, failure patterns become clear. For example, temporary network issues don’t look the same as invalid device tokens. Thanks to observability, you can clearly see this difference.
Key Metrics for Notification System
Delivery metrics
- Send-to-delivery rate: How many notifications do actually reach providers vs. fail beforehand?
- Provider acceptance rate: What percentage of notifications do providers accept vs. reject immediately?
- End-to-end delivery time: Time from trigger to device receipt (P50, P95, P99 latencies)
Engagement metrics
- Click-through rates: Which notifications drive action?
- Opt-out rates: Early warning for notification fatigue
System health metrics
- Queue depth and processing time: Are notifications backing up?
- Provider API latency: Is FCM slow? Is APNS down?
- Retry exhaustion rate: How many notifications fail all retry attempts?
Handling Notification Failures
| Type of failure | Observable metric | Action |
|---|---|---|
| Transient failures (network timeouts, rate limits) |
Retry success rate | Exponential backoff with jitter |
| Permanent failures (invalid tokens, uninstalled apps) |
Token invalidation rate | Device registry clean-up, notifying users via email |
| Partial failures (delivered but not displayed) |
Client-side instrumentation required (e.g., app logs of whether the notification was displayed) |
User education, fallback channels |
Coming Back to a Notification System
Before you decide how you want to implement observability for the notifications, you need to understand what actually matters for your specific use cases. Different notification categories have completely different success metrics; as such, they need to be monitored and handled accordingly.
What Observability Does My App Need?
Notifications serve different purposes, each with unique technical requirements:
1.Transactional notifications (password resets, payment confirmations, order updates)
- Requirements: high reliability, delivery confirmation
- Observability needs: delivery success, latency, failure reasons
2.User engagement notifications (new content, social interactions, friend requests)
- Requirements: personalization, timing optimization, frequency capping
- Observability needs: open rates, conversion tracking, opt-out patterns
3.Marketing and campaign notifications (promotions, announcements, re-engagement messages)
- Requirements: segmentation, A/B testing, scheduling
- Observability needs: campaign performance, user segments, ROI tracking
Common Notification Failures
Let’s take a look at some scenarios when notifications are lost and learn how having a proper observability set up can help troubleshoot them.
Android Doze Mode and FCM Priority-Based Delays
Symptom: Android notifications arrive hours later despite the successful delivery confirmation.
Root cause: Android Doze limits background activity when the phone is not being used. In case of notifications, it would mean that normal priority messages are deferred until the next maintenance window.
Observable pattern: P95 delivery latency spikes for Android devices during off-peak hours.
FCM's 270-Day Token Purge
Symptom: There is a sudden massive drop in Android push delivery rates starting May 2024, with thousands of "NotRegistered" errors appearing overnight.
Root cause: FCM has invalidated tokens that haven’t been used for more than 270 days.
Observable pattern: You’ll notice a spike in unsubscribe rates, as some apps have lost 20%–40% of their Android audience overnight. Delivery success rate jumps up (fewer devices to send to), but absolute delivered count drops significantly.
Building Your Notification System
Notifications are one of those examples of complex engineering that often stays unseen and behind the scenes.
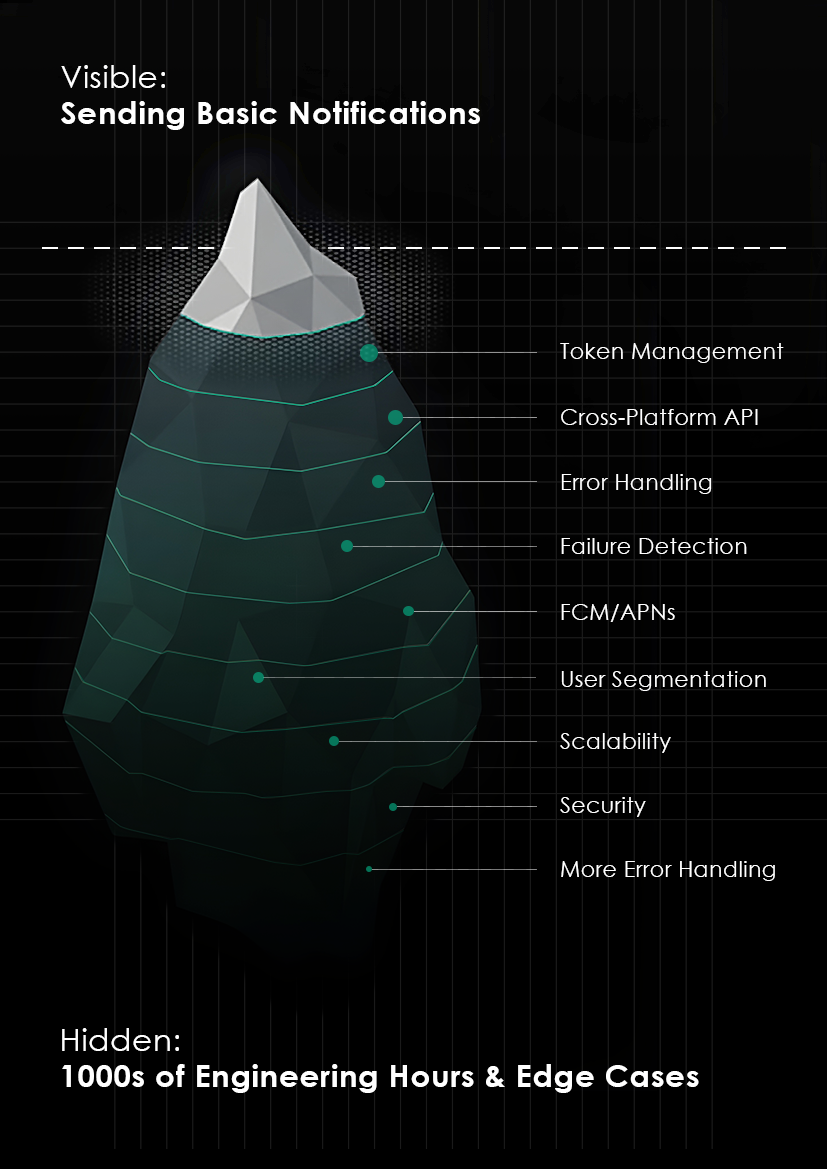
Option 1 - Direct Integration With FCM/APNs
This approach gets the notifications sent; however, as your app grows, you'll likely need a unified API layer to abstract the differences between FCM and APNs payload formats and response handling. You will also need a token management system for storing tokens, handling refreshes, and cleaning invalid tokens across both FCM and APNs.
Queue infrastructure is crucial, too, as it will enable you to handle traffic spikes and priority ordering and ensure notifications aren't lost during outages. Retry logic should be implemented, as well, such as relying on exponential backoff for rate limits and customizing error handling based on different error types from a specific provider.
Finally, you’ll need an observability pipeline, which will enable you to track each notification on different levels of your app. Of course, you should keep in mind the background execution limitations on mobile platforms.
Option 2 - Use a Notification Observability Service (OneSignal, Clix, etc.)
These services simplify notification integration through a unified API, thereby letting you focus on your core product rather than on reinventing the wheel. For most teams, the time saved on debugging delivery issues far outweighs the service costs.
| Criteria | Clix | Firebase Cloud Messaging | OneSignal |
|---|---|---|---|
| Observability | Real-time pipeline visibility | API response only (out of the box) | Dashboard with analytics |
| Token Management | Automatic with health monitoring | Manual | Automatic |
| Debugging | Real-time error insights with AI assistance | Check logs | Basic dashboard |
| Best for | Transactional notifications | Simple apps, zero budget | Marketing notifications |
At first, this comparison might seem like a simple trade-off between features and cost. But there's something it doesn’t capture: the hidden complexities we've just explored above. Those "silent iOS notifications," Android battery optimizations, token rotations, and countless other edge cases don't magically disappear just because you choose a managed service; they’re still there, just handled differently.
The distinction between "sent successfully" and "user saw it" can involve a dozen failure points. Only real-time observability can help you catch and resolve them; luckily, services like Clix focus on the full pipeline visibility.
Conclusion
Real-time observability has become a necessity. Without it, you’re not making decisions that are based on data; you’re operating on hope.
Simple applications can get by with basic logging, but production deployments require real-time monitoring and deeper analytics. The cost of lost notifications (which could be measured in user trust, revenues, and debugging time) could largely exceed the investments in a solid observability infrastructure.
Transactional notifications, such as payment confirmations and OTPs, might have proof-of-delivery requirements for compliance. Critical alerts must guarantee delivery with fallbacks, and marketing campaigns require engagement metrics to demonstrate ROI. That’s why you need to make sure you’ve selected the correct observability level for your needs.